
As the existence and usefulness of recommendation engines have moved from the cutting edge of data science to the mainstream, we have seen a proliferation of plug-and-play products that connect to these recommendation engines.
In this blog article, we will weigh whether recommendation engines should be built or bought off-the-shelf. As with all enterprise systems, this decision involves considering compromises of cost versus features. Here, though, we will explain how to make the right decision based on your company’s underlying data architecture.
Recommendation system = Recommendation algorithms + System engineering
Building a recommendation system or a personalization engine should be understood as the sum of two separate but co-dependent components: algorithms and system engineering.
Most articles and books that discuss recommendation systems tend to focus on algorithms.
To briefly touch upon that angle here, there are a number of models that need to be selected and compiled, including:
- User Journey Tracking
- Affinity (how a user feels about the content they are viewing)
- Content Filtering
- Collaborative Filtering (both user-based and content-based).
While the mathematics here is certainly interesting, it is increasingly well-understood and does not represent the greatest technical challenge in a Recommendation Engine project.
Like all Machine Learning projects, the challenge of getting proven value from recommendation engines mainly involves system engineering. A successful recommendation engine is a systematic project.
In DMI’s experience, after we have designed the algorithms a recommendation service requires, we know that we will face many problems in the data and systems engineering space, including designing cohesive data pipelines, processing performance challenges and data storage problems. As a result of this, the whole system must be planned systematically, and the decision to build or to buy should be made independently of this data architecture process.
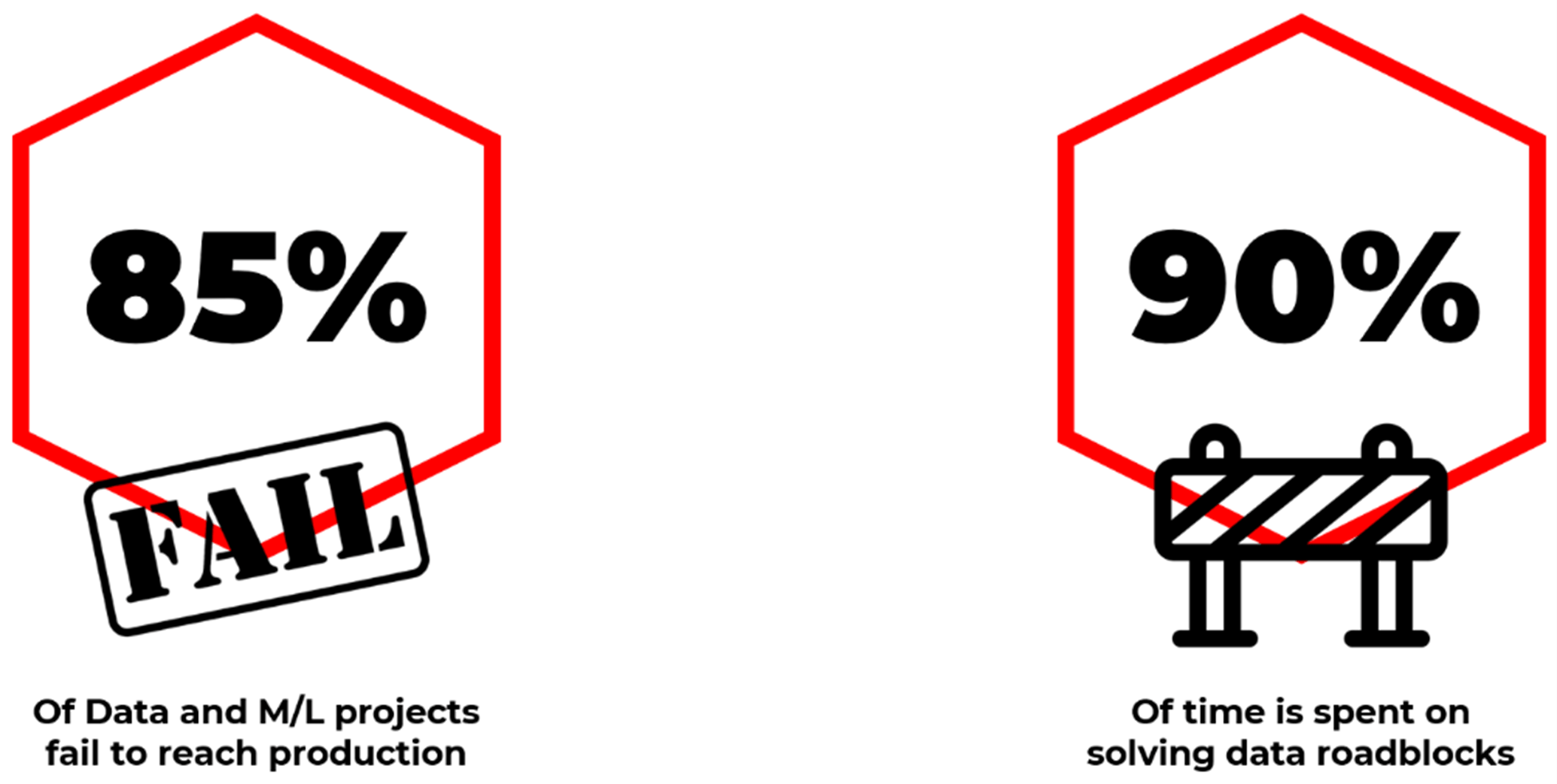
Speaking of data problems, 85 percent of data and Machine Learning projects fail to reach production. And 90 percent of project time is spent on solving data roadblocks.
Assuming that you have appropriately skilled data scientists (or have purchased a suitable off-the-shelf product), your major challenge will come in automating data pipelines and putting your project into production – not writing or installing your algorithms.
That is why, for this article, we are zeroing in on the system engineering pieces required for a solution, as well as on the specific benefits of a configurable platform for your recommendation engine, as opposed to a plug-and-play solution or a bespoke build.
Overall Architecture of a Recommendation System or Personalization Engine
The Architectural needs of a Recommendation Engine are a bit like winning a game of chess. Not only do you need to have the right pieces on the board, but you also need to be very strategic with your moves. Here, the “right pieces” represents data, and “strategic moves” represents schema:

Data
For the overall scope of a recommendation system, the key is the underlying architecture, which starts with the data. This layer contains various datasets, such as:
- User Profiles
- User Journey
- Content
User Profile data can be known (and authorized) demographic data and previous user journey summary data, including items users purchased, their check-out preferences, geographical location, membership details, as well as any other relevant GDPR-compliant data.
User journey data refers to the interaction between users and items. This is the basis of affinity and of estimating whether the user enjoys the content that they are consuming. In a previous post, we discussed that user journey data can include rating systems or like/ dislike buttons while noting that these signals have large drawbacks and so more subtle indirect detection may be more powerful.
Content data is the metadata used to describe the content, including price, color, origins, and any other relevant descriptive data. For example, if the content is a film, the content data would include the Genre, the Director, Actors, Year Made, Runtime, Country of production and any other tagged description data.
Data Engineering
With the three types of data defined, we can move on to the data processing and storage layer. This data is in constant change – not just in terms of volume and actual change (for example in the content that is available), but also in the metadata (feature data) that is being added to make the Recommendation Engine more powerful. This constant change must be carefully engineered to keep the system running without the constant hand-holding of an ML engineer.
Schema
Earlier, we likened recommendation engines to winning a game of chess, stating that you need not only the right pieces on the board (data), but you also need to be strategic with your moves (schema).
Most importantly, the schema must have the capability to deploy algorithms as plug-ins. The machine learning field, including the recommendation field, is enjoying fast development with new algorithms emerging every year. However, these algorithms cannot be easily plugged into or unplugged from the whole system in a flexible manner. They have to be worked upon and personalized on a case-by-case basis.
The architecture also needs to have a capability to service volatile environmental mixes and ever-changing data pipes with service performance that is high enough to provide feedback for each request within milliseconds.

Finally, the architecture must support elastic scaling of its resources – from the ability of the DB, to the ETL layer, to processing and performing layers, to feedback loops. The recommendation engine requires such capable underlying resources, and cloud services can meet this requirement because they can use elastic resources.
CONCLUSION
It is highly unlikely that the data for your recommendation engine will be so standardized that you can avoid data engineering challenges by buying an off-the-shelf solution. Make sure that your design considers the underlying data architecture and ML ops challenges before you consider where you’re going to source your algorithms from. Once you are confident that your algorithms will survive in production, then you can consider where to procure them.
On the other hand, if your algorithms are standard, and if an off-the-shelf solution will work with your data architecture, then that may be a way to reduce both time to market and total cost.
[hubspot type=cta portal=8444324 id=5af1078d-cc0c-40a2-b89f-89ee383b80ad]